
The ELWIS project: General Information
Project Objectives and Issues
ELWIS is an acronym for German Korpusgestützte
Entwicklung lexikalischer Wissensbasen (= corpus-based
development of lexical knowledge bases).
The project is funded by the Ministry of Science and Research
Baden-Württemberg.
The project
has been in existence since the beginning of 1992 at the Department of
Linguistics at the University of Tütbingen, Germany.
Research in the ELWIS framework deals with crucial issues
related to a theoretically sound description of lexical units
for NLP systems using corpus-based methods and tools.
We distinguish two interrelated areas:
- Acquisition:
- Exploitation of existing lexical knowledge
sources (text corpora, machine-readable dictionaries, computer
lexicons) for efficient construction of lexical knowledge bases.
- Representation:
- adequate, theoretically sound descriptions of
lexical knowledge for different types of applications in computational
linguistics.
Both areas were (and still are) investigated in several national and
international projects, but German has only rarely been the object
of such studies. The ELWIS project not only evaluates possibilities of
transfer methods developed for other languages to German, but also
develops and tests new methods and approaches for description.
The linguistic phenomena under investigation are inflectional and
derivational morphology, word formation, syntactic and semantic
valency, collocations and morphosyntactic properties of idioms..
The ELWIS Scenario
The project's different activities yield a prototypical instance of
the reusability scenario shown in figure 1.
Figure 1: ELWIS scenario
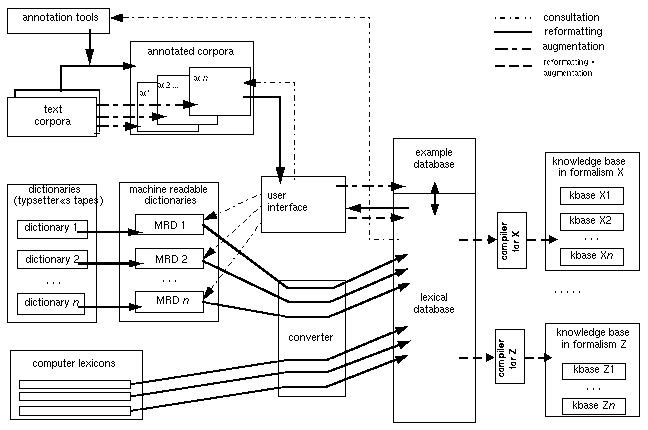
The lexical database is the central part of the scenario: on
the one hand it is the target component for the research experiments
carried out in the field of lexical acquisition; on the other hand the
lexical knowledge stored in the database can be automatically compiled
into lexical knowledge bases with alternative knowledge representation
formalisms. The lexical database in itself is realised by the use of
a relational database management system.
Specific methods and tools are used to extract lexical information
from machine readable resources such as machine readable
dictionaries, existing computer lexicons and machine
readable text corpora and to store the information in the
database. In most cases these resources need additional treatment:
German machine readable dictionaries are available as typesetting
files only and have to be converted into a more appropriate format.
Quality and quantity of information obtainable through automatic
analysis of text corpora is improved considerably if the texts are
linguistically annotated (POS, syntactic and semantic tagging). This
requires the availability of annotation tools for the language under
inspection; the tools in turn can make use of the lexical information
stored in the database.
The information stored in the lexical database will finally be
integrated in lexical knowledge bases by use of compiler
programmes. This two-stage approach was chosen because it has been
shown that direct construction of intelligent knowledge bases
from text corpora and dictionary resources is not feasible. While
these types of systems (i.e., DATR, TFS) were never really tested for
large amounts of data, relational database management systems have
been sufficiently proven to safely administer large amounts of data.
In addition this two-tiered architecture allows to test the
theoretical generalisations expressed in the knowledge bases against
large amounts of data for adequacy of description. This allows
efficient testing of competing theories within a single formalism or
across different ones.
Results and work in progress
Collection of lexical and linguistic resources
One major part of the project is the accumulation of lexical and
linguistic resources for German. The following resources are
currently available:
- Text corpora
- in machine readable form were initally not general available in
sufficient quantities. In addition to various texts which has
assembled from a variety of sources (e. g.: Mannheimer Korpus I
from the Institut für deutsche Sprache at Mannheim, Literary texts
from the Oxford Text Archive, one year of the newspapers
Frankfurter Rundschau and Donaukurier from the European
Data Initiative), all messages from all German news groups accessible
in the Internet are archived within the project. This type of text is
not only suitable for the construction of large text corpora due to
its very machine readable nature, moreover, the richness of topics
covered by the texts, and the fact that most of the texts are unedited
written language is highly unusual; this type of language is
frequently used and rarely studied. Moreover, the texts are highly
idiosyncratic with respect to mark up and orthography and are thus
challenging automatic procedures of text preparation and
normalization.
- Machine readable dictionaries,
- i.e., dictionaries made for humans available in machine readable
format. The Duden editorial provided us with typesetting files
containing parts of the Duden Stilwöterbuch and the
Duden Bedeutungswörterbuch.
Other sources available within the project are machine readable
versions of Gerhard Augst's Morpheminventar A-Z and Verben
in Feldern. Valenzwörterbuch zur Syntax und Semantik deutscher
Verben.
- Computer lexicons,
- i.e., description of lexical units stored in computer files or
databases which are in most cases designed as lexical components of
NLP systems. ELWIS investigates possibilities and limitations of the
exploitation of two existing computer lexicons for German, namely the
Saarbrücker deutsches Analysewörterbuch (SADAW) and the
German part of the lexical data from the Centre for Lexical
Information (CELEX).
Tool Development
Another major work package within the project is the acquisition and
adaption of available software tools, as well as the development of
own software tools required for ELWIS's different fields of study:
- Likely
- is a robust probabilistic part-of-speech tagger for German. It has
been developed by combining well-tested techniques for English with
training data for German which was made available by the Institut
für deutsche Sprache. The output of the tagger, POS-tagged
German texts, will eventually be used as base for the development of
lemmatization and noun phrase extraction tools for huge amounts of
German texts.
- Lexparse
- is a flexible dictionary entry parser which was developed for the
conversion of dictionaries stored on typesetting files. The parser
consults a user-supplied dictionary grammar specifying the
hierarchical structure of the dictionary entries by means of
context-free rewrite rules. The grammar formalism provides schemes for
expressing (multiple) optional rules, sets of terminals, and different
homonym and sense counters. Switches and configuration options allow
the adaption to user-specific needs, e.g. the display of the generated
parse trees is user-configurable and supports SGML and LaTeX output,
as well as hierarchical attribute-value structures. Lexparse was used
for the parsing of the Duden dictionaries and is currently used
for the parsing of other dictionaries.
- Insyst,
- INserter SYSTem, is a unique system for automatic insertion
(i.e., classification) of lexical items under appropriate nodes in
hierarchies as used in modern formalisms for lexical information such
the DATR formalism. It allows efficient (a) testing of generalizations
when designing a lexical hierarchy; (b) transferring large numbers of
lexical items from flat data structures to a finished lexical
hierarchy when using it to build a large lexicon. INSYST was developed
and used to test competing DATR-theories for German noun inflection
within the ELWIS project.
- n-gram
- facilitates the extraction of collocations from texts by means of
statistical calculations: frequencies of clusters of words are
compared with frequencies of individual words in the cluster, pairs of
such frequencies having a high relation are said to have high
mutual information-values and the pertaining word clusters are
automatically selected as candidates for collocations.
- Lexpand
- is a LEXical EXPANDer programme that generates full forms from
the project's lemmatized core database. The database contains a
complete description of the morphological relevant features for each
lemma. Lexpand takes a lemma and its features as its input and
generates all inflected forms for the lemma. Underlying the programme
is a thorough rule system of inflectional morphology for German.
Apart from the above mentioned tools developed within the project,
ELWIS has assembled a large variety of tools for NLP processing
from external sources.
Research
Research is concerned with the following issues:
- Lexical database design:
- For the development of the lexical database, a conceptual schema
(i.e., an entity-relationship-model) was developed by the use of
appropriate methods of semantic data modeling. This conceptual schema
was then transferred into a schema of relations and implemented. It
contains a theoretically sound description of the inflectional
morphology and valency patterns for German, and can easily be adapted
for descriptions of lexical semantics.
- Methodology for the development of dictionary grammars:
- based on meta-lexicographical findings on the structure of
dictionaries, a method was explicated for the development of grammars
for the dictionary entry parser Lexparse. The method was employed for
the development of dictionary grammars for the two Duden
dictionaries.
- Tag Sets for German Corpus Tagging:
- for the part-of-speech tagger developed in the project a revised
set of tags of 42 syntactic categories for German was developed. This
tag set is based on an earlier set developed in the 1970s at the
University of Saarbrücken and was revised on a strictly
distributional basis. The set will serve as a starting point for noun
phrase extraction and other syntactic tools.
- Methods for the automatic extraction of idioms and collocations:
- automatic extraction of idioms and collocations was the target of
a series of experiments: it was shown that corpus-based statistical
methods which have been tested for English can not simply be applied
to German data. A number of additional problems must be solved first.
A combination of corpus- and dictionary-based methods seems to be more
appropriate for the extraction of this type of lexical entries.